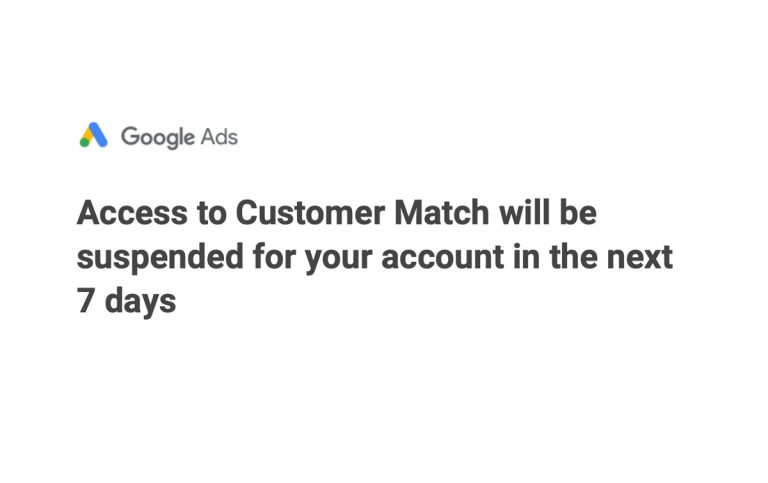
Access to Customer Match will be suspended for your account in the next 7 days – Google Ads Alex Centeno Read More »